Recommendation Info About How To Build A Web Crawler

How To Build A Web Crawler In Python From Scratch - Datahut
Scrapy Python: How To Make Web Crawler In Python | Datacamp

Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse
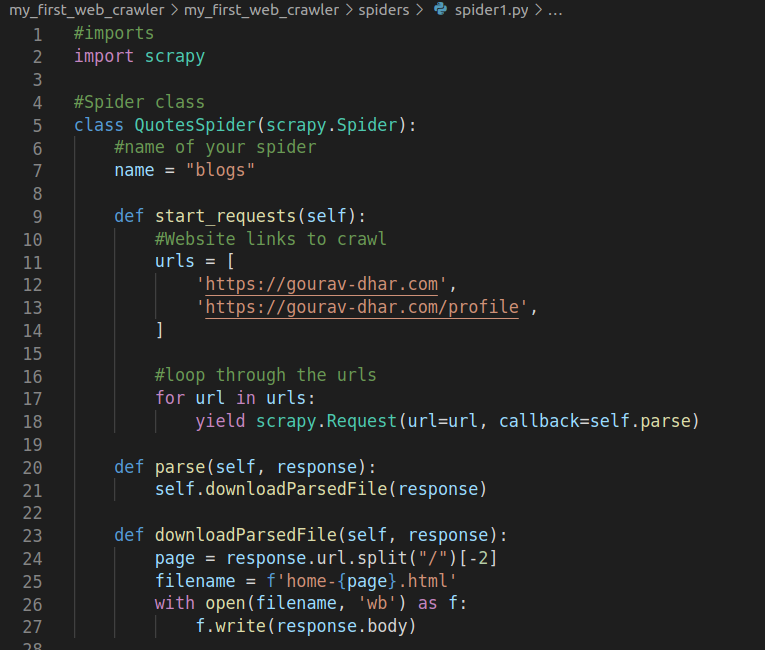
How I Created My First Web Crawler! | By Gourav Dhar Level Up Coding

How To Build A Simple Web Crawler | By Low Wei Hong Towards Data Science

The first thing to do when configuring the request is to set the url to crawl.
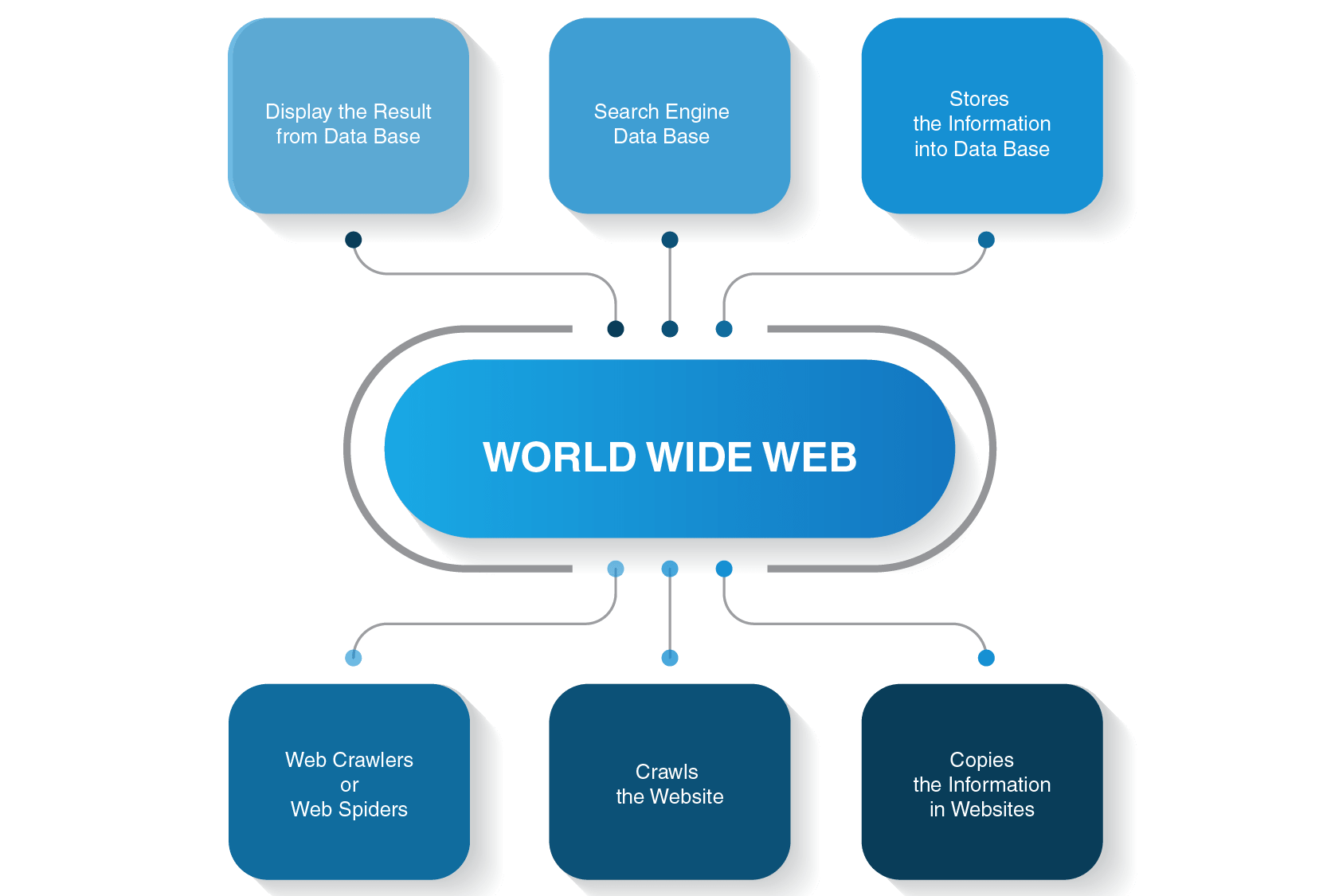
How to build a web crawler. The working mechanism for web crawlers is simple. Trandoshan is divided in 4 principal processes: The robust means the ability to avoid spider.
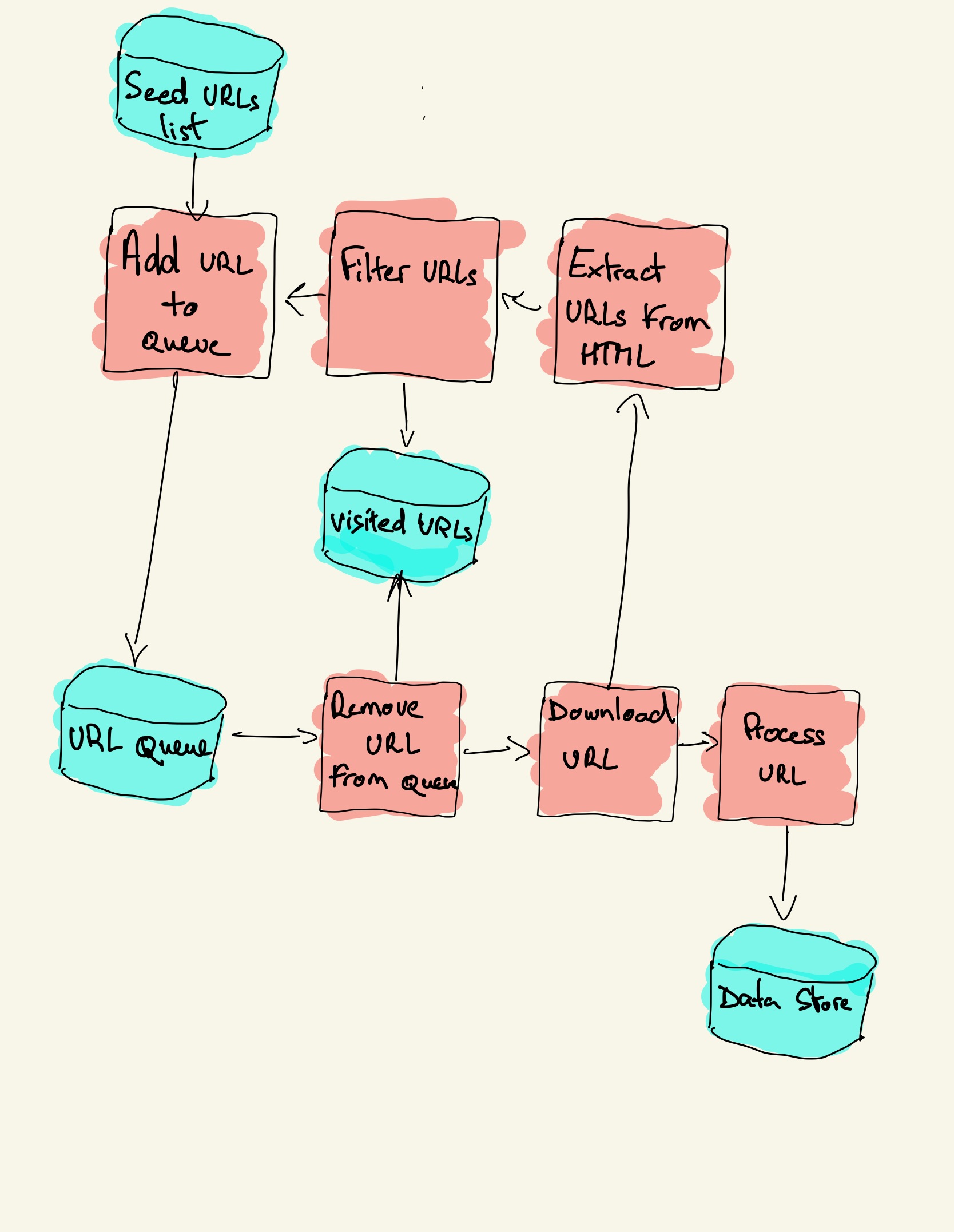
The process responsible of crawling pages: Here are the basic steps to build a crawler: How does a web crawler work?
Pop a link from the urls to be visited and add it to the visited urls thread. The web crawler should be kind and robust. You might need to build a web crawler in one of these two scenarios:
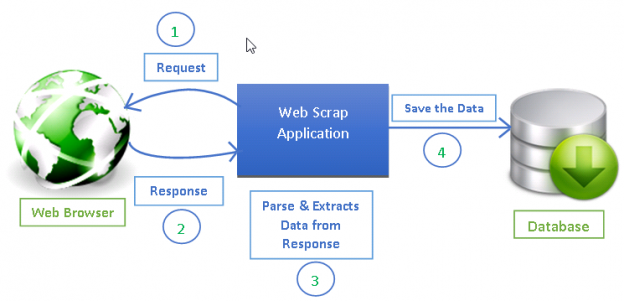
It read urls to crawl from nats (message identified by subject todourls),. Now, to the tutorial’s core, we will build a web crawler that uses the bfs algorithm to traverse web pages. A web data extraction service provider, like us at promptcloud, takes over the entire build and execution process for you.
In this video we'll be learning about how web crawlers work and we'll be covering the different types of link that our web crawler will have to be able to de. Octoparse is a powerful and useful scraping tool that allows you to extract different types of. The diagram below outlines the logical flow of a web crawler:
We’ll also use the uri.create () method to. We can do so by calling the uri () method on the builder instance. This is provided by a seed.
First, click on the page number 2, and then view on the right panel. A web crawler can be written in java, c#, php, python, or even javascript. All you have to do is provide the url of the site you.
The first thing to do when configuring the request is to set the url to crawl. Here are tools which you can use to build your own web crawler: This is not easy since many factors need to be taken into consideration, like how to better leverage the.
We can do so by calling the uri () method on the builder instance. These seed urls are added to. Here, kindness means that it respects the rules set by robots.txt and avoids frequent website visits.
The crawler will begin from a source url that visits every url. The crawler needs somewhere to start; Add one or several urls to be visited.
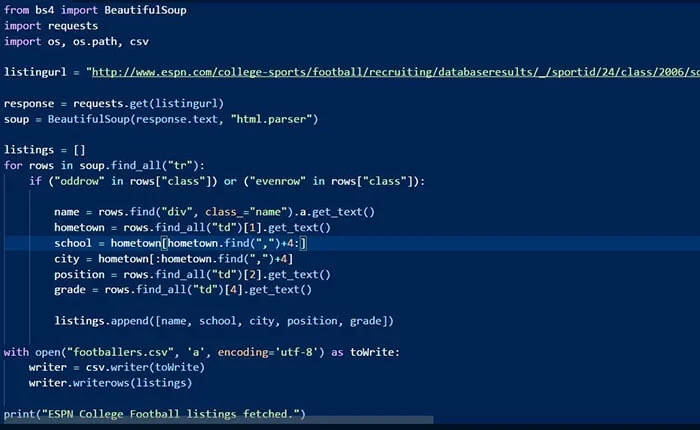
Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse

Build A Crawler To Extract Web Data In 10 Mins | By Octoparse Dataseries Medium

Python Programming Tutorial - 25 How To Build A Web Crawler (1/3) Youtube
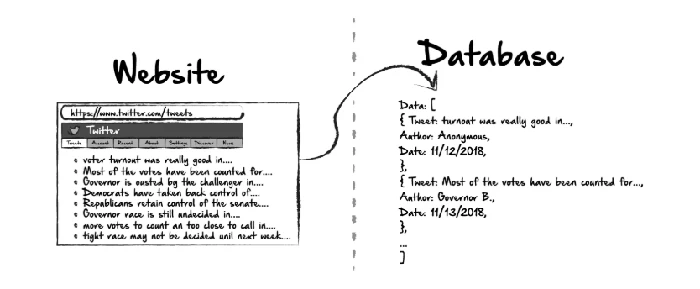
Web Crawling With Python | Scrapingbee
Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse

Web Crawler - Wikipedia

Scaling Up A Serverless Web Crawler And Search Engine | Aws Architecture Blog

How To Build A Web Crawler In Python From Scratch - Datahut

How To Build A Web Crawler? - Scraping-bot.io
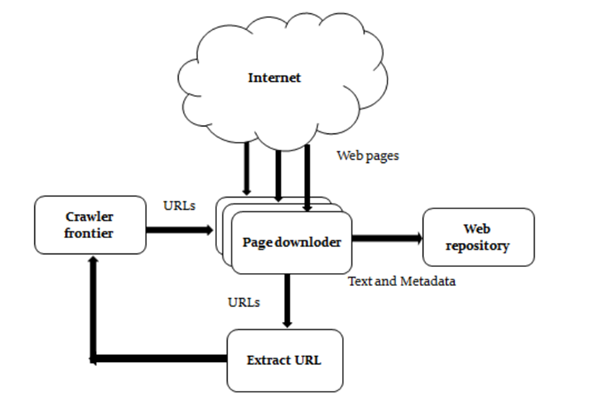
From 0 To 1: How Build A Web Crawler Scratch By Python. Part I. | Lena Li Medium
How To Build A Serverless Web Crawler | Cloud Guru

How To Build A Web Crawler In Less Than 100 Lines Of Code

Make Your Own Web Crawler - Part 1 The Basics Youtube